요즘 AI기술은 너무나도 빠른 속도로 발전하고 있습니다. 이런 시대의 흐름에 편승하기 위해 기초적인 지식에 대해 습득하고자 합니다. 이번 글에서는 RAG(Retrieval-Augmented Generation, 검색 증강 생성)에 대해 주로 알아볼 예정이며 Fine-Tuning과의 비교를 하고자 합니다.
Fine-Tuning이란?
Fine-Tuning은 이미 학습된 대규모 언어 모델(LLM, Large Language Model)을 특정 작업에 맞게 조정하는 과정입니다. 이 과정에서는 새로운 데이터를 추가적으로 학습시켜, 기존 모델이 다루지 못했던 특정 도메인이나 작업에 대한 성능을 향상시킵니다. Fine-Tuning의 장·단점은 다음과 같습니다.
- 장점
- 도메인 특화 모델을 만들 수 있다.
- 최신의 지식을 습득할 수 있다.
- 단점
- 비싸다.
- 어렵다.
- 데이터 의존적이다.
- 확장성이 적다.
위의 장·단점에서 이야기하듯 우리만의 도메인 특화 모델을 만든다는 것은 매우 큰 장점입니다. 특히나 의료, 법률 등 일반 사람들이 접근하기 어려운 부분은 특히나 그러하지만 단점도 동시에 존재합니다. 일단 가장 큰 단점은 너무 비싸고, 너무 어렵다는 점입니다.
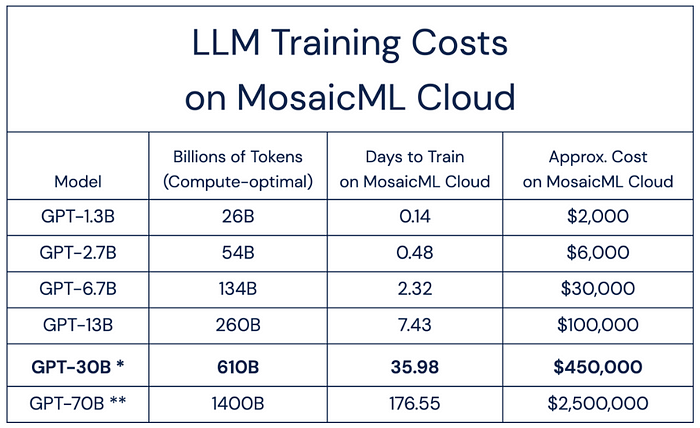
2023년의 GPT에 대한 Fine-Tuning 테이블입니다.
물론 현재로서는 기술이 많이 좋아져 2~7B의 LLM이면 충분한 성능을 보여준다고 하니 해당 테이블로 가볍게 계산해본다면
2.7B = $6,000 → 880만원 (환율 1467원 기준)
6.7B = $30,000 → 4400만원 (환율 1467원 기준)
정도 됩니다.
또한, Fine-Tuning을 위해서 이용되는 기술들 또한 어렵고, 복잡한 기술이 많고 주로 사용되는 기술은 클라우드, 분산 학습, 경량화, 양자화 등 각각이 하나의 분야를 이룰만큼 복잡한 기술들인데 이를 할 줄 아는 기술자를 구하는 것도 매우 힘듭니다.
2025년에 이르러서는 점점 가격은 낮아지고 방법은 간편해지겠지만 여전히 어려운 부분이 많기에 대기업이 아닌 기업에서는 택하기가 쉽지 않은 것이 현실인 것으로 보여집니다.
또한, 도메인 특화 모델이다보니 범용성이 많이 떨어지는 경우도 생기고 데이터의 보안 문제, LLM의 환각현상 등이 발생하면서 RAG라는 개념이 대두되기 시작했습니다.
RAG란?
RAG란 Retrieval-Augmented Generation의 약자로 한글로 해석하자면 검색 증강 생성이라고 이야기할 수 있습니다. 기존의 LLM들은 굉장히 방대한 양의 데이터를 학습하고 학습한 데이터를 기반으로 우리에게 답변을 생성해 주었고 저의 경우 이를 Parametric Memory를 이용한 응답이라고 이야기합니다. 그러나 RAG는 외부 지식을 이용한 방법으로 이미 LLM은 충분한 양의 지식을 가지고 있고 추가적인 정보만 제공한다면 더욱 훌륭한 성능을 낼 수 있다고 이야기하는 방법론이라고 할 수 있습니다. 저의 경우에 있어서는 이를 Non-Parametric Memory를 이용한 응답이라고 주로 표현합니다.

위의 그림이 RAG를 가장 손쉽게 이야기하는 그림이 아닐까 싶은데요. query는 우리의 질문, 로봇이 LLM, 뇌가 Parametric Memory, 책이 외부 지식 즉, Non-Parametric Memory를 뜻하며 이러한 외부 지식을 이용하는 방법으로 얻을 수 있는 장·단점 은 다음과 같습니다.
- 장점
- 지식을 습득하기 쉽다.
- 출처를 명확히 제시할 수 있다.
- 보안 수준이 높다.
- 단점
- 높은 퀄리티의 문서가 필요하다.
- 문서 관리가 수시로 필요하다.
장·단점에서 볼 수 있듯이 어느 지식이던 쉽게 습득하기 좋다는 점이 가장 큰 장점이라고 할 수 있습니다. 문서만 존재한다면, 그것을 참고문헌으로 주어 답변할 수 있고 최신의 지식 또한 손쉽게 습득 가능하며 그리고 출처를 명확히 할 수 있기에 환각현상도 완화시킬 수 있게됩니다.
그러나 이러한 장점에도 불구하고 단점도 여전히 존재합니다. 높은 퀄리티의 문서가 필요하나 이를 구하는 것이 매우 어려운 편에 속하며 특히나 도메인에 특화된 문서일수록 더더욱 그렇다고 할 수 있습니다. 또한, 문서관리가 필요하고 RAG의 핵심 기술인 임베딩 관리가 요구됩니다.
두 방법 모두 분명한 장·단점이 분명하게 존재하고 그래서 어느 것이 좋다던가 혹은 서로 비교를 한다던가 하는 부분은 이제는 크게 중요하지 않다고 생각합니다. 두 방법 모두 적절하게 사용하는 것이 적절할 것입니다.

위의 사진이 전체적인 RAG의 과정을 단순하게 표현한 도식입니다. 해당 그림에서 Retriever, Data Source 부분이 매우 중요한데 이 부분을 리트리버와 벡터스토어라고 주로 표현한며 이는 RAG에 있어서 매우 중요한 부분이기에 이에 대해서는 다음 글에서 이어 다루도록 하겠습니다.
추가적으로 RAG에 대한 소개영상이 필요하다면 아래의 유튜브 영상을 매우 추천합니다!